The Spring AI ETL Pipeline or Extract, Transform, and Load framework is used to convert or parse large amounts of data into chunks. It is heavily used to process raw data sources to Structured Vector Store and ensure data is in optimal format for RAG or Retrieval Augmented Generation.
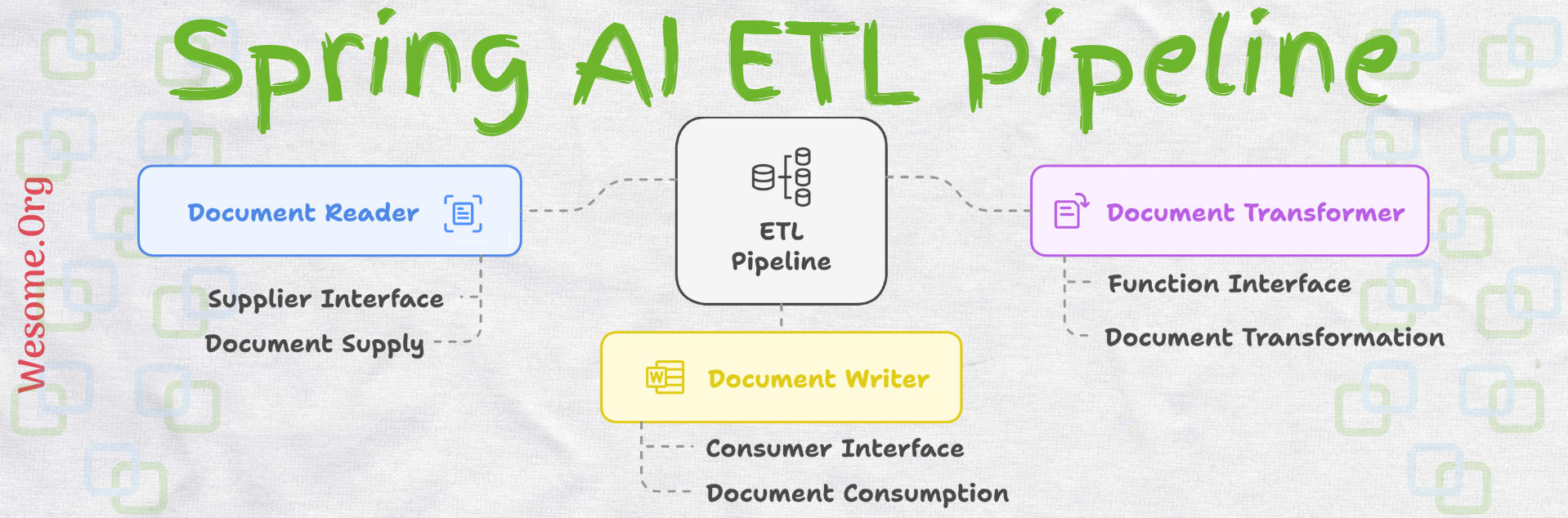
There are three main components of the Spring AI ETL Pipeline
- DocumentReader that implements Supplier<List<Document>>
- DocumentTransformer that implements Function<List<Document>, List<Document>>
- DocumentWriter that implements Consumer<List<Document>>
Document Reader
The Document Reader is the first stage of the ETL process flow, it reads the source of documents from multiple types such as JSON, Text, Markdown, PDF, and Apache Tika which includes DOCX, PPTX, HTML, etc.
Transformers
The Transformers convert the batch of documents into another format as part of the process flow such as TextSplitter, TokenTextSplitter, ContentFormatTransformer, KeywordMetadataEnricher, SummaryMetadataEnricher.
Writers
The Writers is the last stage of the ETL process flow, it stores the processed documents into respective storage systems, such as File, Document Markers, or VectorStore